From OpenClaw to Your Own Assistant
A personal assistant should be like a person: one channel, one conversation — it answers everything you ask in a single ongoing thread; in this project that channel is Telegram by default. Under the hood, it's an evolving knowledge base, wired into the network, that happens to talk back.
The bet: own the one layer that doesn't churn — your data. The model keeps evolving, the harness is throwaway glue, even the CLI underneath could swap out — but the folder stays yours.
How it started
Anthropic banned OpenClaw, the tool I'd been running my assistant through — and with it went the freedom to reach my own Claude. The fallbacks shut the same door: Hermes wouldn't take my Claude OAuth either, and the raw API meant metered cost I couldn't predict — riding an SDK that keeps piling on features I never asked for.
So I built my own on Claude Code, and kept both doors open: by default it runs on my subscription's OAuth — nothing a vendor can quietly cut off again — but the harness doesn't care what's behind it, so swapping to an API (Anthropic's, or a cheaper one like DeepSeek) is a single env var. OAuth or API, it's my own Claude, my choice. That's the freedom I was after.
The result is Persona (MIT, github.com/gaxxx/persona). The code was the easy part. What's worth writing down is why it has to be yours, and how little it actually takes.
Why it's yours
Most personal-AI products want to be the system of record: your life pours into their database, hostage to someone else's uptime and business model. Persona is the other way round — the one thing that makes it yours is your data, plain Markdown in a folder you control: readable, greppable, deletable. The assistant is disposable; the data is permanent.
Everything above the data is swappable — the model is a commodity you can trade down, the harness is throwaway glue, and even the skills are distilled from your own logs, so the judgment survives any format. Freedom isn't running the strongest model — it's being able to swap it.
The architecture
The reflex is to reach for a framework — an agent graph, a vector DB, a queue. I reached for none of it. Claude Code already is a long-lived process that reads and writes your files, speaks MCP, loads file-based skills on demand, and ships a memory model worth stealing. The "framework" collapses into a few hundred lines of glue — three background processes sharing one folder:
┌──────────────┐ ┌──────────────┐ ┌──────────────┐
│ tg-daemon │ │ cron-daemon │ │ watchdog │
│ Telegram I/O │ │ scheduled │ │ bash loop │
│ long-poll + │ │ prompts from │ │ that respawns│
│ claude -p │ │ CRON.md → │ │ dead daemons │
│ subprocess │ │ one-shot │ │ + pings me │
│ │ │ claude -p │ │ on Telegram │
└──────┬───────┘ └──────┬───────┘ └──────┬───────┘
└─────────┬───────┴─────────────────┘
│
┌──────┴───────┐
│ shared disk │
│ (Markdown) │
└──────────────┘
- tg-daemon long-polls Telegram; each message is one turn against a persistent
claude -pthat reads my profile, picks a skill, and replies. - cron-daemon fires scheduled prompts from
CRON.md— the morning digest, the kids' reminders, the daily journal. A cron is just a prompt with a clock on it. - watchdog restarts either daemon if it dies and pings me — a plain bash loop, no LLM, $0 to run.
Two ideas keep those few hundred lines standing up.
It forgets on purpose. Like a person after a night's sleep, it drops the short-term churn and keeps what matters: the inner Claude rotates on a budget — turns, hours, tokens, however short or long I set it — then rebuilds from disk on a recipe I choose. Nothing's lost in the reset, because the durable layer is the folder, not the context window — and that memory is files you can cat, not embeddings: when it surprises me, I open the exact fact and delete it. You cannot cat a vector.
You grow your own skills. A skill is just a Markdown prompt. The assistant improves not from a bigger model but from skills shaped to you — distilled from your own conversation logs, or generated by whatever meta skill-builder you point at them, until each one fits your life instead of a vendor's defaults. A correction you make once becomes a rule; a need you keep hitting becomes a skill that's already there next time.
The bill is the punchline
Because it runs on Claude Code, the daemon can tally what every turn would have cost at Opus list price. One instance, after about a week of real use:
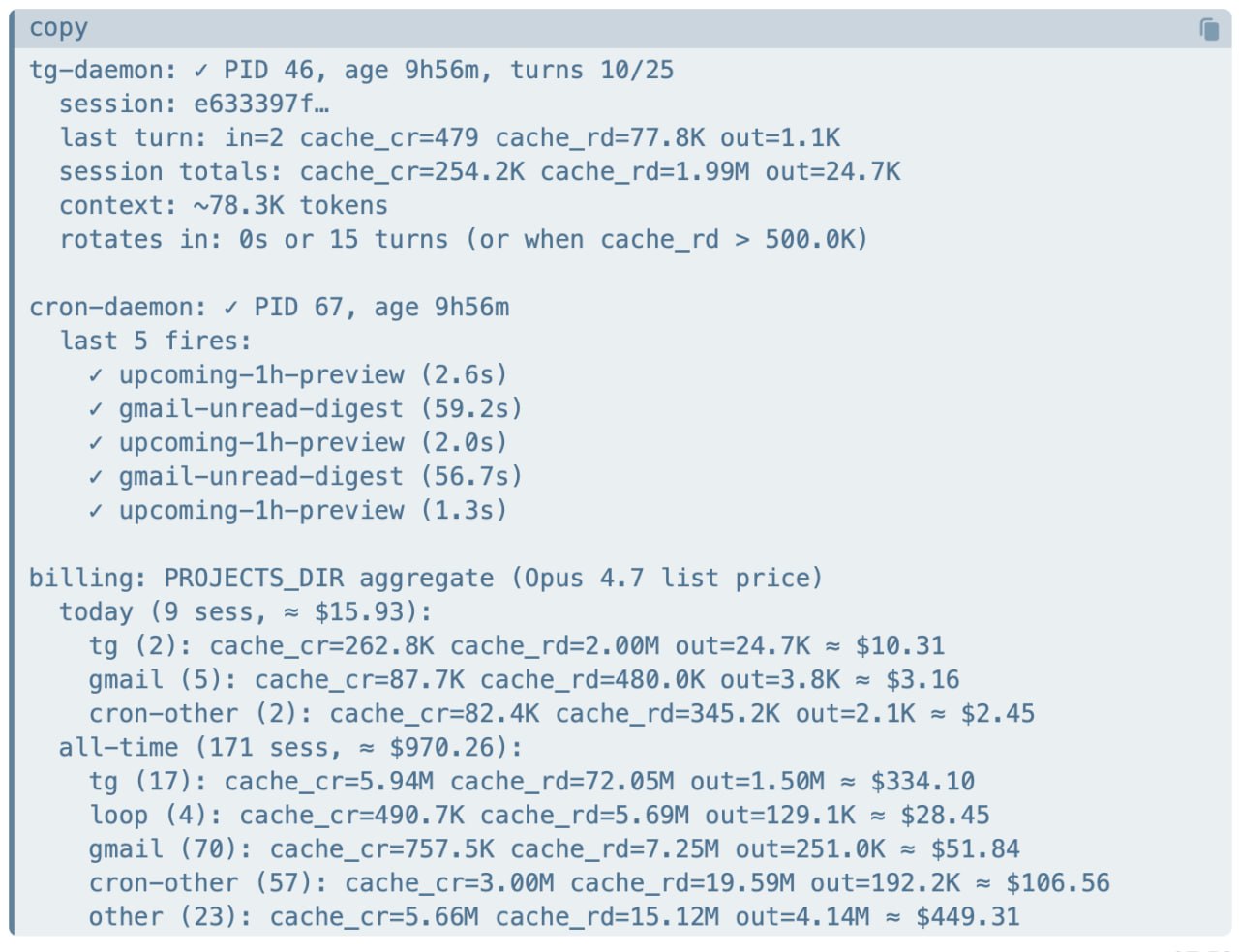
That's the list price, not my bill. For a while it ran on my $100-a-month Claude Code subscription — already a world away from $970. Then I turned the one metered knob: each instance now runs a different brain behind the same harness — my wife's on Claude Pro with Opus, my own on DeepSeek for text and Gemini for vision — and the whole thing came down to about $30 a month. The expensive part is, by design, the one part you can swap.
How: two moves
Strip everything away and the recipe is almost insultingly short: connect Claude Code to your Telegram, and put your data in a folder it owns. Clone Persona and you inherit zero facts about me — point it at your folder and it becomes yours. Same code, your life.
Repo and a 3-minute setup video: github.com/gaxxx/persona