Raft Implementation Notes (6.824 2021 Spring)
November 05, 2021
中文
Completed my new year's resolution: Implement raft & raft based distributed kv store.
Background
Here's a screenshot to prove I did it.
| raft | kvraft | shardkv |
|---|---|---|
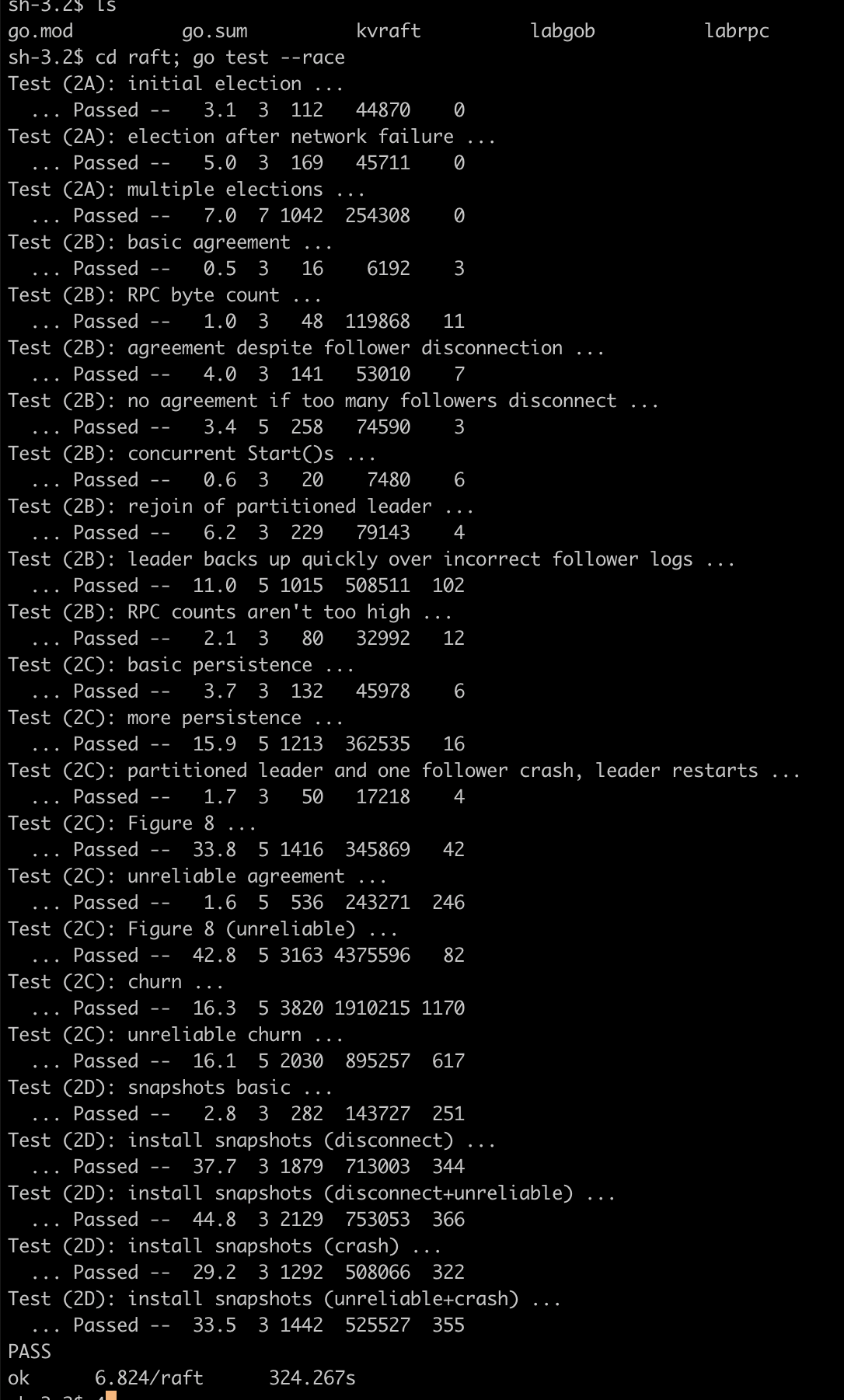 |
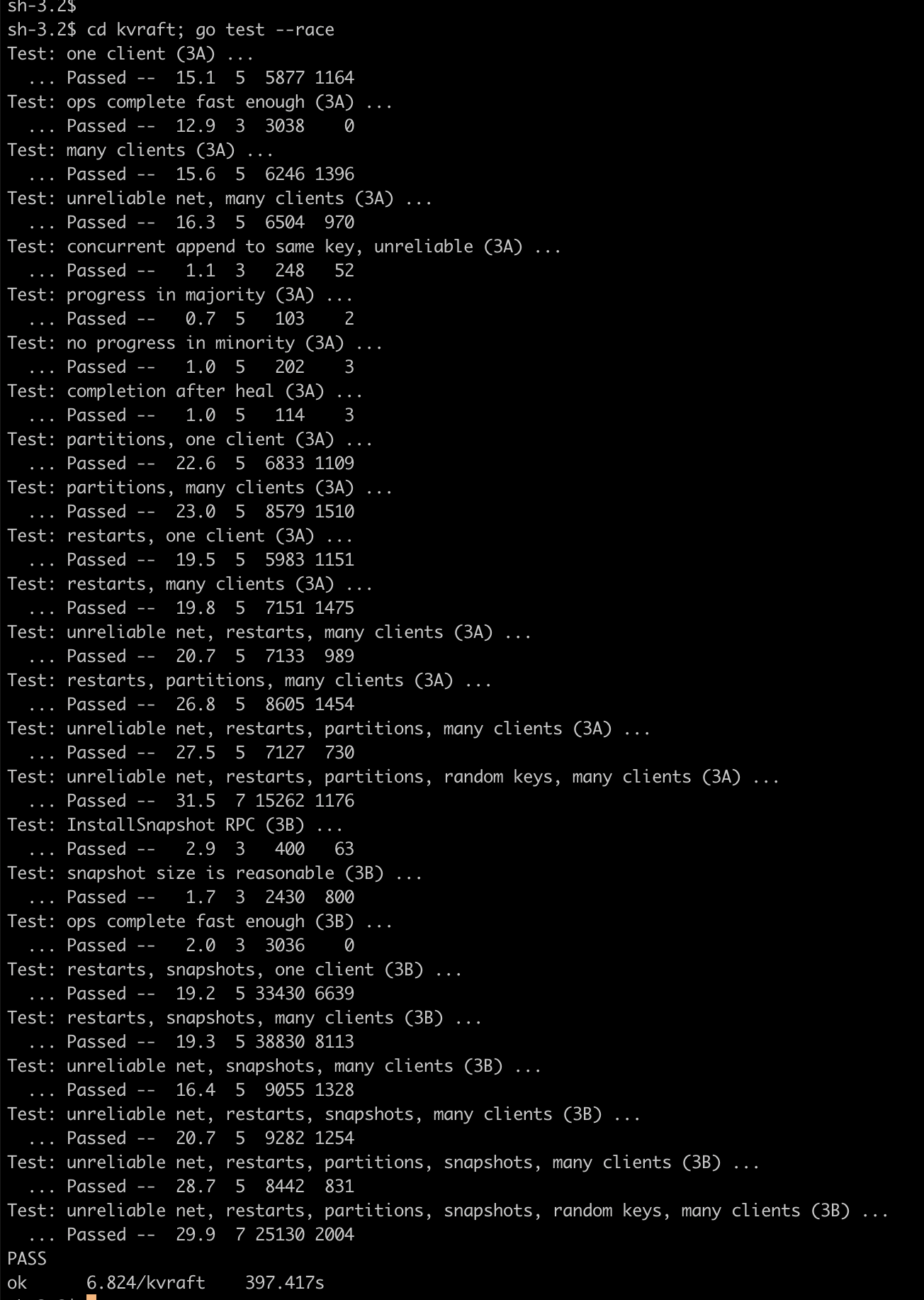 |
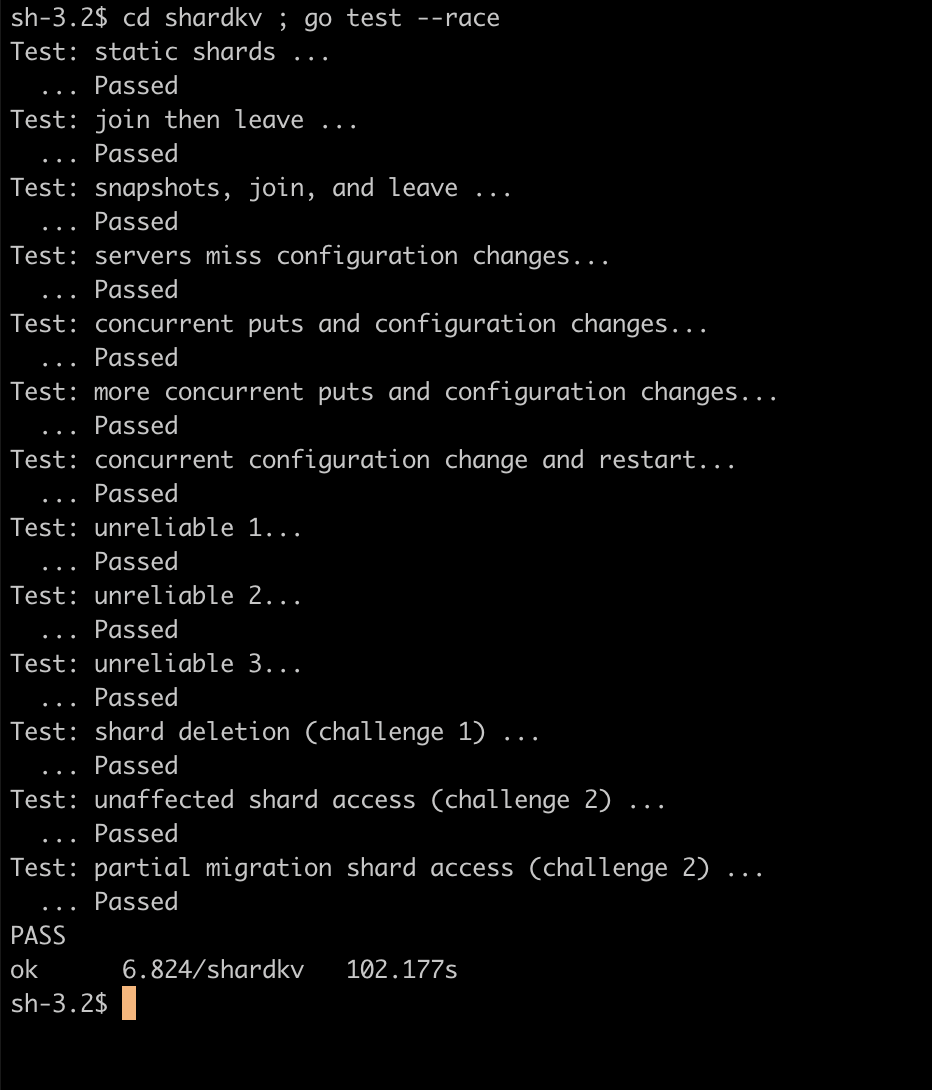 |
Goals
Study the 6.824 course and related distributed systems knowledge, and based on the lab environment:
- Implement distributed log replication with Raft
- Implement a distributed KV store based on Raft log
During the process, I encountered these issues and had some thoughts:
- Tests pass once but fail occasionally when run 10 times
- How to handle deadlocks, how to manage locks across different modules
- When a leader is working normally, a rogue leader sends a high-term request - how to recover quickly
- How to implement ZooKeeper or Kafka with Raft
- How to do performance tuning
- How to scale
I developed views on all of these during implementation - you can jump to the final section...
Below is the implementation for each test, where I briefly describe:
- What needs to be done
- Technical details
- Pseudocode
- Implementation of technical details
Implementation
Reflections
- Tests pass once but fail occasionally when run 10 times
- Raft detail handling
- Occasional failures are usually persistence issues. The Raft paper's commit condition is "when the log is replicated." When handling heartbeats, if you return without persisting and report the latest log position to the leader, the leader may directly apply. If a crash occurs at this point, problems arise.
- However, persisting on every heartbeat with new data can be slow, especially on ARM machines. And this is a problem that only occurs when two machines fail simultaneously, so some implementations just write to memory.
- Another approach is async persistence, confirming data replication in the next heartbeat. This is correct but fails tests because it's slow. In practice, if clients aren't latency-sensitive, it works.
- How to handle deadlocks, how to manage locks across modules
- External interaction
- Just don't expose locks to other modules. Theoretically, the lock scope is: shardkv > kvraft > raft
- When a leader is working normally, a rogue leader sends a high-term request - how to recover quickly
- How to implement ZooKeeper or Kafka-like functionality with Raft
- Raft's logid is similar to ZK's lastId. For writes, establish a connection with the leader, execute, and get a logid as write_id. For Gets, establish a long connection with a follower - as long as all Get requests have idx greater than write_id, it works...
- Kafka cluster with 3 servers - after one crashes, others take over; 3 servers can tolerate 2 failures. Kafka achieves this with ZK. Raft can also have a shardctrl in front to test peers. If 2 of 3 fail, shardctrl can add a new group with just the surviving peer.
- How to do performance tuning
-
For a piece of data, commit time is:
- client —request—> leader
- leader → persist
- leader —heartbeat—> peer
- peer → persist
- peer —heartbeat reply→ server
To improve performance:
- Use SSD or memory for persistence
- Do async persistence (increases client latency)
- Reduce network latency, reduce peer count; peers can connect to other raft groups
-
- How to scale
- For heavy writes, use multi raft groups
- Get requests can go to followers if real-time consistency isn't critical
- Use multi-level raft groups with different OnMessage strategies and different granularity for Save Snapshot